During the past few months I’ve been working (by bursts) on a system that generates PDF documents in interaction with a Windows-based CRM. I thought it would be interesting to share some bits from a technical point of view.
Constraints
- the in-house CRM system is Windows-based
- the CRM comes with a 2000ish Java API allowing CRUD operations on the data it hosts
- some XML data comes from a third-party system via HTTP
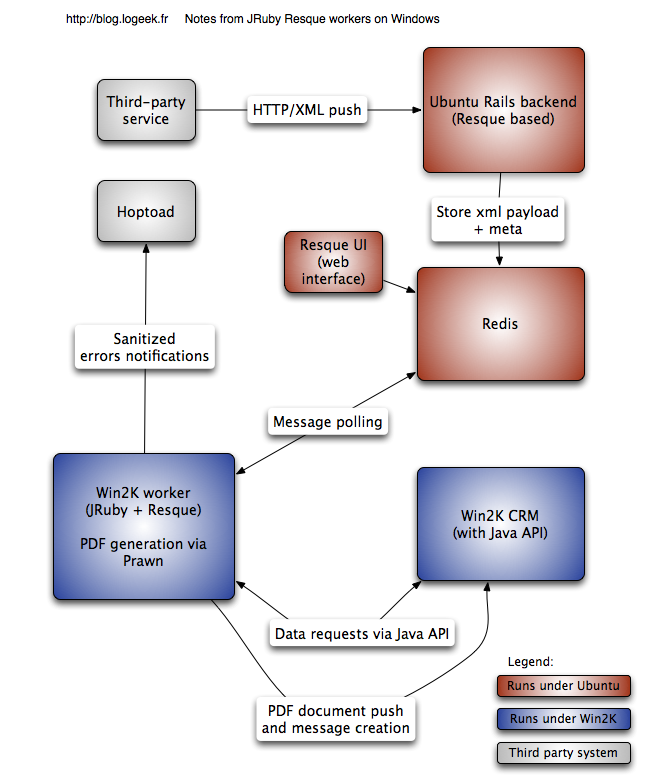
The big picture
After a bit of thinking, I came up with an architecture that mixes Ubuntu and Windows:
- the front-end uses a very simple Apache + Passenger + Rails app that pushes incoming messages into Resque (also hosted on Ubuntu)
- a JRuby/Windows Resque (~v1.5) worker grabs the messages, talks to the in-house CRM using the Java API, and generates the PDF using Prawn
This way I can benefit from the reliable, well-tested app hosting for the front-end using Passenger, while keeping Windows for the worker part that really requires Windows. Another nice point is that Resque allows to increase the number of workers if needed to scale.
Starting and keeping the Windows/JRuby worker up
To keep the JRuby worker alive, I chose to rely on FireDaemon Pro and came up with a configuration that seems to work fairly well:
- use
C:\Program Files\jruby-1.4.0\bin\rake.batas the executable - pass parameters
resque:work - uncheck “enable event logging” in advanced (otherwise FireDaemon will consider a process that doesn’t log in the event log is dead)
We’re also using Nagios on top of that to monitor what’s going on.
Resque tweaks (for Windows)
The version 1.5 of Resque relied on ps – I made a patch to rely on the
built-in wmic.exe instead:
wmic PROCESS get Processid,CommandLine /format:csvFull patch available here.
Redis tweaks
- I switched Redis to append only file to ensure a reboot with pending messages won’t lose the messages (the performance is still largely good enough for our use case here)
- I encoded the incoming XML data (latin1) to base64 to avoid any deserialization issue with latin1 specific characters – the data is then iconv converted by the worker
Conclusion
Mixing stacks with different strengths can be useful to tackle a problem: here hosting the front-end on Windows would have been harder to get right in my opinion, while running the worker on Ubuntu was not possible in this case.
JRuby is great to build nice-to-use, well-tested APIs on top of factorish legacy Java APIs.
Prawn works equally well on JRuby and on MRI.