Today I am pleased to announce the release of Kiba Pro v2.
Kiba Pro provides vendor-supported extensions for Kiba ETL, a popular Ruby-based Open-Source solution to author and maintain data pipelines (learn more about Kiba ETL and why businesses are using Kiba ETL).
Kiba Pro v1 was soft launched with a few select clients, so consider v2 to be the first public official release!
“Kiba and Kiba Pro helped us with our biggest database migration from MySQL to Postgres, by reducing the migration time from couple of days to less than one hour, all while increasing data quality. We're now also using Kiba Pro to build and update our internal datawarehouse, with full in-house control of the data flow.”
Christos Kornaros / Developer & Data Engineer at ![]()
If your company uses Kiba ETL, please consider subscribing to Kiba Pro, as this will fund more work & maintenance on Kiba ETL itself and increase the overall long term sustainability of these efforts!
New component: Parallel Transform
Kiba Pro’s ParallelTransform leverages concurrent-ruby to provide an easy way to parallelize block transforms. It focuses on accelerating IO-bound operations like HTTP queries or database operations with one tiny code change:
# Regular Kiba ETL transform
transform do |row|
...
end
# Kiba Pro parallel transform (single line change)
parallel_transform(max_threads: 10) do |row|
...
endHere is a Youtube extract showing the actual acceleration on a concrete example:
This is the first released parallelization construct for Kiba. More are planned.
New component: Bulk SQL Lookup
A very common requirement when moving data around is the ability to translate “external references” (e.g. public-facing product references a.k.a natural keys with “business meaning”, 3rd party identifiers, or even primary keys of a given source database) into “internal” ones (e.g. your target database primary keys).
This process is applicable to loads of situations: when synchronizing data between apps, when migrating data from a database to another, or when building datawarehouses.
Kiba Pro’s BulkSQLLookup achieves this transformation in batches (by groups of XYZ rows), to avoid slowing down your pipeline like a N+1 query would do in web development.
This component leverages Sequel, our favorite Database Toolkit for Ruby, and should work with all Sequel-supported databases (although we only support Postgres and MySQL officially at this point).
Let’s take the following products SQL table:
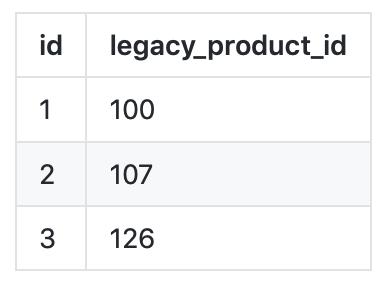
One can setup a transform like this:
job = Kiba.parse do
# fake source records, lacking the primary key we need
source Kiba::Common::Sources::Enumerable, -> [
{external_id: 100},
{external_id: 107},
{external_id: 126}
]
transform Kiba::Pro::Transforms::SQLBulkLookup,
database: db,
table: :products,
buffer_size: 2_500,
# this is the Hash key in the input row
row_input: :external_id,
# the name of the SQL column where we'll search the value
sql_input: :legacy_product_id,
# the name of the SQL column to be returned
sql_output: :id,
# and where to store it in the resulting Hash
row_output: :product_id
...
endSuch a transform will give us rows with the following content (with a single SQL query for every group of 2500 input rows):
{external_id: 100, product_id: 1}
{external_id: 107, product_id: 2}
{external_id: 126, product_id: 3}Full documentation is available here.
We will demo this component in more depth in upcoming blog posts or videos.
New component: FileLock
FileLock provides an easy way to ensure a single block of code runs at a given time on a given server (= no overlap), something which is often needed for ETL jobs. For instance:
- You may have long-running incremental data synchronisation jobs, which will store a last_updated_at timestamp on disk. You would not want this timestamp to be modified by two concurrent jobs (or the data synchronisation would not work as expected).
- You may query a remote resource (server etc), for which you may need to avoid more than one connection at a given time.
Note that FileLock is not a distributed lock. A Postgres/MySQL-based lock will be shipped in a next version of Kiba Pro for that purpose.
Here is how to use the FileLock:
require 'kiba-pro/middlewares/file_lock'
Kiba::Pro::Middlewares::FileLock.with_lock(lock_file: 'tmp/process.lock') do
job = prepare_job
Kiba.run(job)
endNo more jobs stacking up!
Full documentation is available here.
Components already available in Kiba Pro v1
3 components were already available before, but it’s worth mentioning them here since it is the first public announcement on this blog:
- SQL Source provides an efficient way to read large volumes of rows (using streaming, cursors, or whatever type of extraction you’ll write out of the Sequel DSL)
- SQL Bulk Insert/Upsert Destination provides an efficient way to insert or upsert to Postgres and MySQL. Unlike other solutions, you can easily pre-process rows, handle multiple destinations in a single pass, handle the flushing of related tables to ensure you won’t get into foreign key ordering issues.
- SQL Single-Row Upsert Destination provides a very easy to use upsert of single records for Postgres (for simple cases)
Please reach out if you have any related question!
Big thanks go to…
I want first and foremost to thank Mike Perham (Sidekiq’s author). Mike has actively provided guidance and help on my road to releasing Kiba Pro. I was able to study the way Mike has structured his offering, ask a few questions, and even copy his landing page design with his blessing (at least until I get a more personal one). I am very grateful, so many thanks!
I also want to thank the authors and contributors of all the tools I currently rely on: the Ruby language itself (Matz and contributors), Sequel by Jeremy Evans, the folks at Concurrent Ruby which I’m starting to leverage. I hope to contribute back more to these tools if I sell enough subscriptions myself!
Finally, special mentions to:
- My wife Cécile for her casual listening when I needed a bit of reflexion.
- QoQa Services SA and Innosys: these consulting clients have been the most instrumental in their support to my research!
- Anthony Eden, former maintainer of ActiveWarehouse-ETL (spiritual inspiration of Kiba ETL).
- All the Kiba ETL users out there who took the time to write a testimonial!
In my next posts, I’ll share more concrete use of these components on actual cases, so consider subscribing below!
Be safe,
– Thibaut